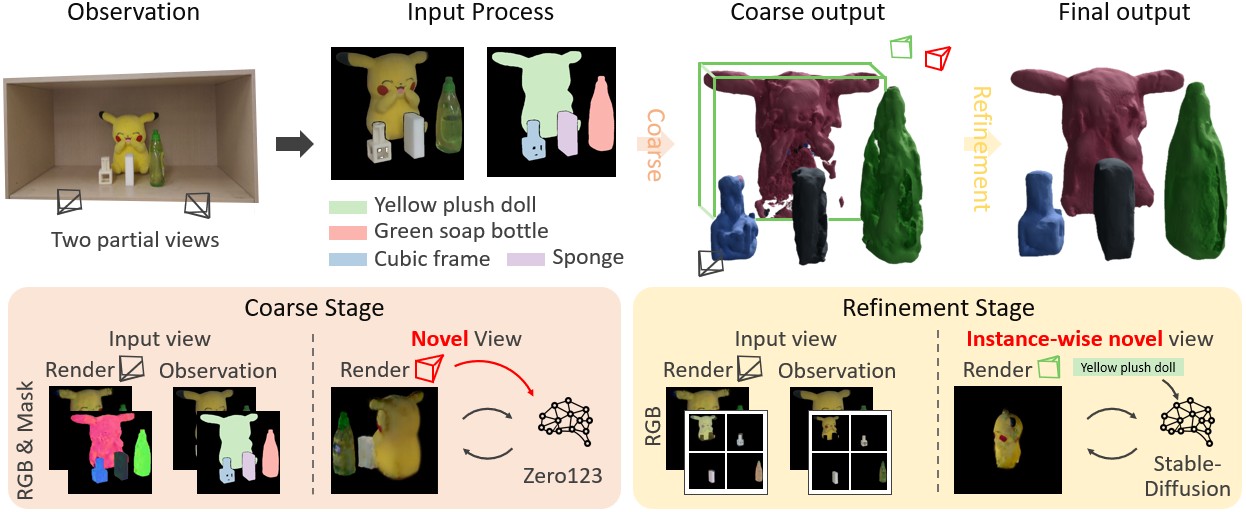
Overview of DreamGrasp
Overall pipeline of DreamGrasp
(Observation) Our method uses only two partial-view
RGB images as input. (Input process) Instance masks and text prompts are extracted from the
RGB images using SAM and ChatGPT, respectively. (Coarse stage) These inputs are
used for initial scene-level geometry reconstruction, leveraging RGB and instance mask images
with novel-view supervision guided by Zero123. (Refinement stage) The coarse scene is segmented
using learned features, and each object is refined through instance-wise RGB input and novel-view
supervision guided by a text-conditioned diffusion model.
Recognition Results
DreamGrasp consistently outperforms all baselines across
varying object counts. While CGC struggles with geometry prediction under partial views, Zero123*
performs competitively at the scene level. However, its performance drops significantly in instance-
wise geometry prediction, emphasizing the importance of the refinement stage


